
As the world races to unlock the boundless potential of artificial intelligence (AI), a new challenge looms on the horizon: the insatiable power demands of this rapidly advancing technology. The explosion of generative AI models like ChatGPT has thrust concerns about AI’s voracious appetite for energy into the spotlight, prompting a crucial shift in how chipmakers approach power efficiency.
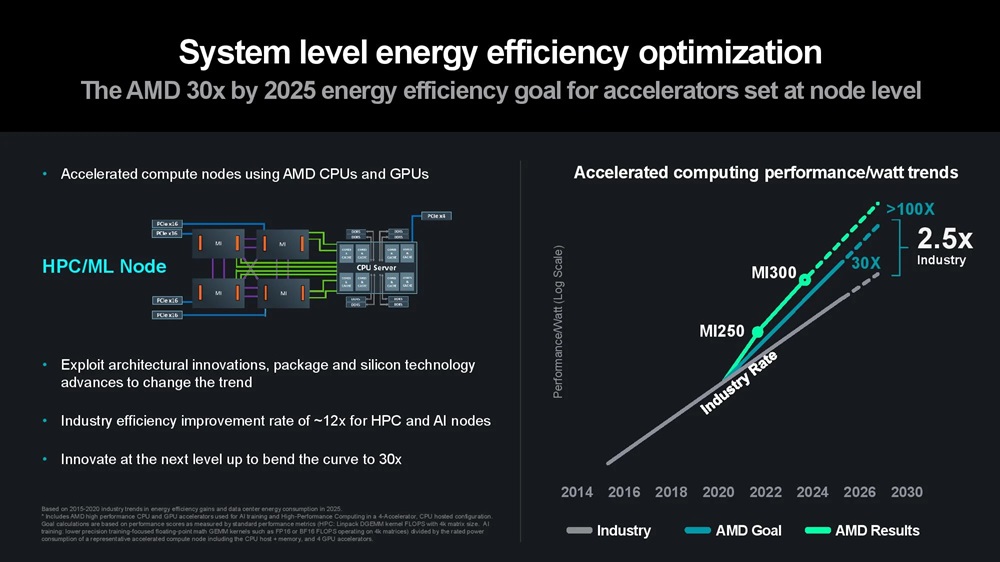
AMD, a pioneer in the semiconductor industry, recognized this impending crisis as early as 2021. Foreseeing the looming problems with AI’s skyrocketing power consumption, the company embarked on an ambitious mission: to achieve a staggering 30-fold increase in compute node power efficiency by 2025, a goal dubbed “30×25.”
However, as the landscape evolved, AMD’s vision grew even bolder. The company now sees a pathway to surpass its initial target, aiming for a remarkable 100-fold improvement in power efficiency by 2026 to 2027. This audacious objective underscores the urgency of addressing AI’s escalating thirst for energy.
The driving force behind this urgency is the rapid expansion of data centers, fueled by the world’s largest companies vying for AI supremacy. As these tech giants race to gain an edge, they are constructing vast data centers at an unprecedented rate. However, public power grids are ill-prepared for this sudden surge in demand, making power the new limiting factor in the AI revolution.
There are hard limits on the amount of power available to data centers, with grid capacity, infrastructure, and environmental concerns restricting the capacity that can be dedicated to both new and expanding facilities alike. This has led to a startling trend: many new data centers are being built adjacent to power plants to ensure a reliable supply of energy, while the crushing demand has even reignited the push for nuclear Small Module Reactors (SMRs) to power individual data centers.

“We have the opportunity to drive that ecosystem by bringing many different capabilities and many different expertise’s together. I think that’s the key for the next generation of innovation.”
Dr Lisa Su
The problem is exacerbated by the exponential growth in the compute required to train AI models. While the size of early image and speech recognition models doubled every two years, mirroring the pace of computing power advancements over the last decade, the size of generative AI models is now growing at an astounding rate of 20 times per year, outstripping the pace of computing and memory advancements.
According to AMD CEO Lisa Su, today’s largest models are trained on tens of thousands of GPUs, consuming up to tens of thousands of megawatt-hours. However, as model sizes continue to expand, training could soon require hundreds of thousands of GPUs and several gigawatts of power for a single model – a scenario that is simply unsustainable.
AMD’s multi-pronged strategy to address this power efficiency challenge encompasses a broad approach that extends beyond silicon architectures and advanced packaging strategies. It incorporates AI-specific architectures, system- and data center-level tuning, and software and hardware co-design initiatives.
At the silicon level, AMD is banking on 3nm Gate All Around (GAA) transistors as the next step in improving power efficiency and performance, coupled with advanced packaging and interconnects that enable more power-efficient and cost-effective modular designs. Advanced packaging plays a crucial role in scaling out designs to produce more computing power within the constraints of a single chip package, and AMD employs a mix of 2.5D and 3D packaging to maximize the amount of compute-per-watt it can extract from each square millimeter of data center silicon.
Optimizing for data locality can yield tremendous power savings by reducing the energy required to transfer data between server nodes and racks. AMD’s MI300X exemplifies this approach, with its 153 billion transistors spread across 12 chiplets paired with 24 HBM3 chips, providing 192GB of memory capacity – all available to the GPU as local memory. This extreme compute and memory density, combined with power- and performance-optimized Infinity Fabric interconnects, keeps more data close to the processing cores, minimizing the energy required for data transfer.
However, hardware optimizations alone are not enough. AMD’s work on hardware and software co-optimization yields impressive results, with lower-precision numerical formats like FP4 delivering up to a 30-fold increase in power efficiency compared to FP32. While lower precision can result in lower accuracy, advanced quantization techniques have helped address this issue, with MXFP6 producing similar accuracy to FP32 and ongoing efforts to improve the accuracy of even lower-precision formats like MXFP4.
Lisa Su acknowledges that continuing the pace of power efficiency improvements will require an industry-wide effort, bringing together experts from various fields – process technology, packaging, hardware design, architecture, software, modeling, and systems design. “We have the opportunity to drive that ecosystem by bringing many different capabilities and many different expertise’s together. I think that’s the key for the next generation of innovation,” Su said.
As the race to unlock the full potential of AI accelerates, AMD’s efforts to bend the curve of innovation through power efficiency underscore the critical role of chipmakers in shaping a sustainable future for this transformative technology.

